数据库原理
第二章关系数据模型
关系完整性约束
- 第一范式规则:列元素为最基本的单元不能含内部结构
- 行查询时无序
- 行(元组)唯一
- 实体完整性规则:A是R的主键,那么A不能为空
键(主键:主观选用的键):能够区分表中每一元组的属性集合
超键:表中只存在唯一的键 - 参照完整性规则:F是R的外键,且是S的主键(R和S有可能相同),则对于R中每个元组在F中的值取空或者等于S某个主键
关系代数
投影运算
π():简单来说就是从表中取属性(可能多个)去重,如果是多个属性得到的是属性对πA,B(R) ={(a1,b1),....}
SELECT语句默认是不去重,关系运算是去重的选择(限制)运算
SELECT:σF(R),选择表R中满足F的元组
σ Cour = Information (Student):选择学生表中来自信息系的学生元组连接:从两个关系的笛卡尔积中选取属性间满足一定条件的元组
自然连接R⋈S:选取相同的属性作为中间人来连接两个表,自然连接要求至少有一个同名同域属性,且去重
条件链接R⋈F S:只要你写条件,哪怕属性名不同,只要值域兼容就能连
外连接不仅保留匹配的行还保留未匹配的行
左外连接(保留左边匹配右边没匹配的)、右外连接(相反)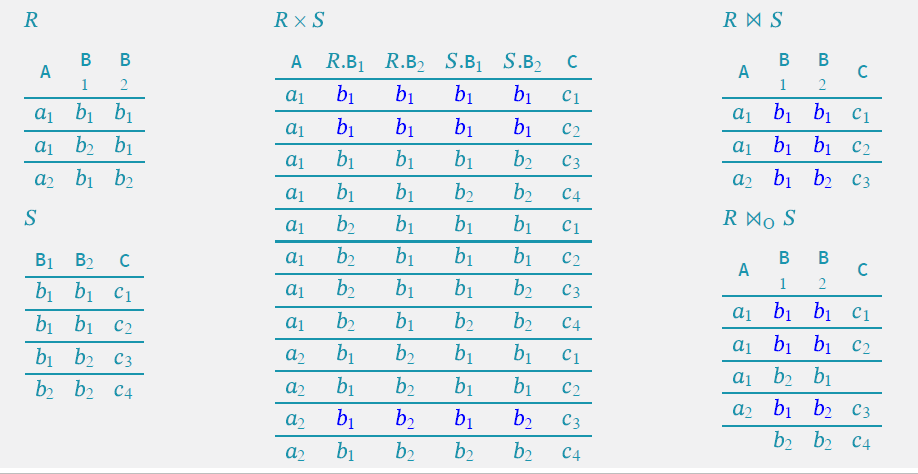
除运算:B ÷ A例 πSno, Cno(SC) ÷ K 先对SC关系在Sno和Cno属性上投影,然后对其中每个元组逐一求出象集,再找出包含K的属性(对)
关系演算*
ALPHA 语言 :
检索
GET W(num) (elements) (if) 查询个数,查询对象,满足条件
GET W (SC.Cno): 查询所有被选修课程的课程号码RANGE Student X:用元组变量X简化关系名Student,后面可以直接用X代替
例: 查询计算机系 (CS) 所有学生都选修了的课程的课程号和课程名1
2
3GET W (Course.Cno, Course.Cname):
∀ StudentX (StudentX.Sdept = 'CS'
→ ∃ SCY (SCY.Sno = StudentX.Sno ∧ SCY.Cno = Course.Cno))集函数
函数名 功能 COUNT 对元组计数 TOTAL 求和 MAX 最大值 MIN 最小值 AVG 平均值 更新操作
- HOLD(更改必须用HOLD)读取到工作空间
- 宿主语言修改
- UPDATE语句送回数据库进行更新
1
2
3HOLD W (Student.Sno, Student.Sdept) : Student.Sno = '2020007'
MOVE 'IS' TO W.Sdept
UPDATE W插入
PUT WW为已经修改好的元组(插入元组)删除
- HOLD读取到W
- DELET W
第三章SQL语言
| SQL功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE, DROP, ALTER |
| 数据操纵 | INSERT, UPDATE, DELETE |
| 数据控制 | GRANT, REVOKE |
创建、修改、删除基本表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29--创建基本表
CREATE TABLE SC
(
Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY (Sno, Cno),
/*定义主键,必须满足表级完整性*/
FOREIGN KEY (Sno) REFERENCES Student (Sno),
/*表级完整性约束条件, Sno是外键, 被参照表是Student*/
FOREIGN KEY (Cno) REFERENCES Student (Cno)
)
--修改基本表
ALTER TABLE <表名>
[ADD <新列名> <数据类型> [完整性约束]]/**/
[DROP <完整性约束名>] /*删除,SQL没有提供删除属性列的语句*/
[MODIFY <列名><数据类型>] /*修改原有的列定义(修改数据类型)*/
--创建索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>]]...)
/*
UNIQUE 索引值只对应唯一一条数据记录
CLUSTER 创建聚簇索引(查询快,更新代价大,索引即数据,数据即索引)
*/
CREATE UNIQUE INDEX Student ON Student(Sno);
/* 为Student表按学号升序创建唯一索引 */查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38-- IN
/*查询IS,MA,CS系的学生姓名和性别*/
SELECT Sname, Ssex
FROM Student
WHERE Sdept IN ('IS','MA','CS');
-- 字符匹配
--1. % :任意长度字符串(可以为0)
--2. _ :任意单个字符
--3. ESCAPE换码
LIKE 'DB\_Design' ESCAPE '\' ;
/*表示'\'是换吗字符跟在后面的字符取原本意思*/'
-- ORDER BY
/*对查询结果排序 ASC DESC*/
-- GROUP BY [HAVING]
/*对查询结果进行分组(满足某些条件)*/
SELECT cno, AVG(score)
FROM Selcou
GROUP BY cno
HAVING AVG(score) >= 85;
--连接查询和EXISTS IN
⚠️ EXISTS必须关联外层表,否则会全表匹配 / 报错。
SELECT s.name
FROM student s
WHERE EXISTS (
-- 只判断是否存在,不返回具体ID
SELECT 1 FROM score sc
WHERE sc.student_id = s.id -- 关键:关联外层表
);
--JOIN ON 外连接
SELECT s_id
FROM score
JOIN course ON score.c_id = course.c_id
WHERE course.c_name = '语文'
表结构说明(所有题目共用)
- 学生表 student
s_id 学生编号
s_name 姓名
s_age 年龄
s_class 班级 - 课程表 course
c_id 课程编号
c_name 课程名 - 成绩表 score
s_id 学生编号
c_id 课程编号
score 分数
【题目 1】(中等偏难)
查询至少选修了 “语文” 和 “数学” 两门课的学生姓名。要求:分别用 IN 和 EXISTS 各写一种写法。
【题目 2】(难,经典面试题)
查询只选修了 1 门课的学生姓名。(注意:不是 “至少 1 门”,是恰好 1 门)
【题目 3】(难,坑点多)
查询没有选修任何课程的学生姓名。要求:
用 NOT IN 写
用 NOT EXISTS 写
说明两种写法在NULL 值下的区别和风险
【题目 4】(很难,综合考察)
查询选修了全部课程的学生姓名。(即:没有任何一门课程是这个学生没选的) 提示:这是经典的 **“全称量词” 转存在量词 ** 问题,必须用 NOT EXISTS 嵌套。
1 | -- 第一题 |
视图
虚关系,在创建视图的时候不执行其中的SELECT语句只是给个基本框架,到查询的时候再进行数据查询1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20CREATE VIEW <视图名> [(<列名>[,<列名>]...)]
AS <子查询>
[WITH CHECK OPTION];--表示在对视图进行更新插入删除操作的时候满足视图定义的谓词条件(子查询中的条件表达式)
--行列子集视图:建立在一个表上且只对行列进行的选择
--也可以建立在多个表上,说明视图的属性列避免冲突
CREATE VIEW IS_S1(Sno, Snmae , Grade)
AS
SELECT Student.Sno, Sname, Grade
FROM Student, SC
WHERE Sdept = 'IS' AND
Student.Sno = SC.Sno AND
SC.Cno = '1'
DELETE VIEW IS_S1
--更新VIEW同更新表
UPDATE IS_S1
SET snmae = 'aaa'
WHERE sno = '11451';
SQL定义约束
非过程性和过程性完整性约束
- 前者在创建表的时候定义,在任何对表执行 INSERT/UPDATE/DELETE 操作时,自动触发检查,确保数据始终满足约束条件
- 后者在对相关数据进行操作的时候自动进行的判断
断言
根据 SQL 标准,断言创建后,任何对断言中所涉及的表执行数据修改操作时,都会触发断言检查,具体如下:
1. 触发的操作类型
只要执行以下任意一种操作,且操作涉及断言 CHECK 子句中引用的表 / 数据,就会触发检查:
- INSERT:插入新数据时,检查插入后的数据是否满足断言条件
- UPDATE:更新数据时,检查修改后的数据是否满足断言条件
- DELETE:删除数据时,检查删除后剩余的数据是否满足断言条件
2. 检查的核心逻辑
- 断言的
CHECK条件必须在任何时刻都为真,只要有一次操作导致条件不成立,该操作就会被 DBMS 拒绝执行,数据不会被修改。 - 断言是声明式约束,由数据库自动触发,无需手动调用,也不支持
BEFORE/AFTER等自定义时机(区别于触发器)。
1 | --创建断言语法 |
1 | --使用SQL断言机制定义完整性约束 |
约束检测时机
控制数据库什么时候检查约束是否合法:
立即检测(默认)
执行一句 SQL,马上检查约束,不满足就直接报错回滚。
延迟检测
先不检查,等到 ** 事务提交(COMMIT)** 时再统一检查。
适合:先破坏约束、最后再修复的场景。
比如你前面那题:先改选课表、再改学生表,中间会短暂违反外键,就需要延迟检测。
1 | --定义约束的时候可以指定立即检测或者延迟检测 |
触发器
更加灵活,可以跨表循环,针对更加基础的单一操作进行检测
1 | --当向选课表 SelCou 插入一条记录时,自动输出 “新增选课成功” |