第一章 引论
编译和解释
- 编译方式的特点
- 目标程序是机器语言-> 编译阶段和运行阶段
- 目标程序是汇编语言程序->编译、汇编和运行
故编译程序生成的目标程序不一定是机器语言程序还有可能是汇编语言程序
- 解释方式
- 按源程序边翻译边执行,立即执行,直接输出
- 不生成目标代码,但是也需要进行语法、词法和语义分析
编译程序工作过程
position := initial + rate * 60
词法分析
识别单词(单词表),即:属性字:<类别号, 自身值>
<id,1> <:=> <id,2> <+> <id,3> <*> <number,4>语法分析
涉及到语法描述:
BNF范式 和 扩充BNF范式:利用递归的方式定义语法
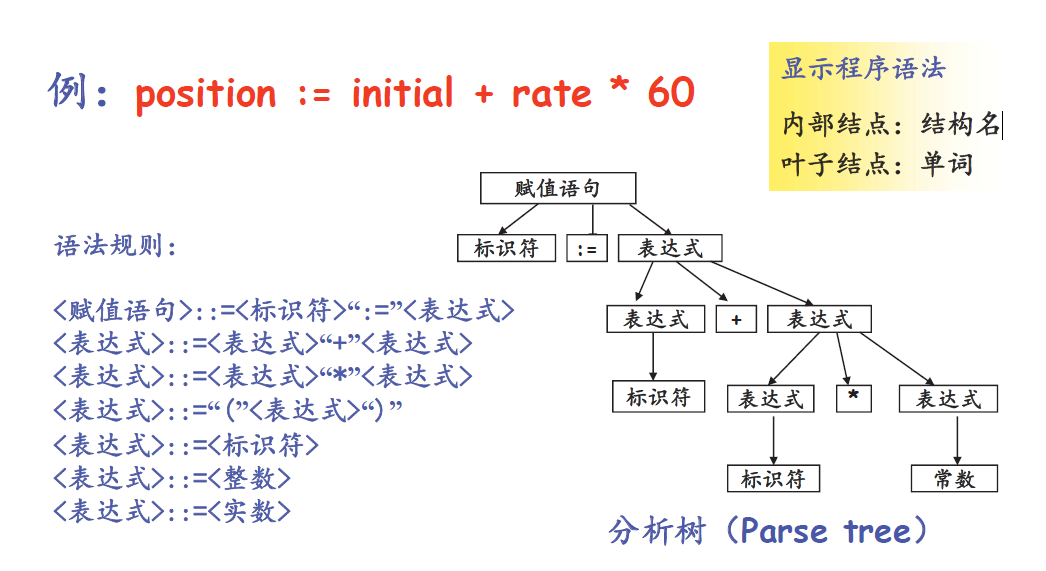
通过语法树对于法进行分析
语义分析
简化语法树,优化结构变得更加精简
用另一种内部形式表述出来或者直接用目标语言表示出来
确定类型、类型和运算的合法性,识别含义并做静态检查
例如 int + float 时自动将int 转化为float类型
中间代码生成(不一定有)
把 树 变成一条条语法
代码优化(不一定有)
优化的是中间代码/目标代码的代码质量
目标代码生成
源程序->(中间形式)->目标指令
目标指令可能是绝对代码、可重新定位的指令代码或者汇编指令代码
表格管理
登记源程序中出现的每个名字以及其属性
为了优化代码的局部和全局优化,以及构建控制流图,会划分基本块
划分基本块的原则是:
- 入口语句:程序的第一条语句;任何跳转语句的目标语句;跳转语句之后紧跟的那条语句。
- 基本块范围:从一个入口语句开始,直到下一个入口语句前或程序结束。
单遍和多遍 :对源程序和中间产物的扫描次数
编译程序的前后端
1 | 词法分析-| |
高级语言具有自编译性
1 | S_T H:宿主语言 |
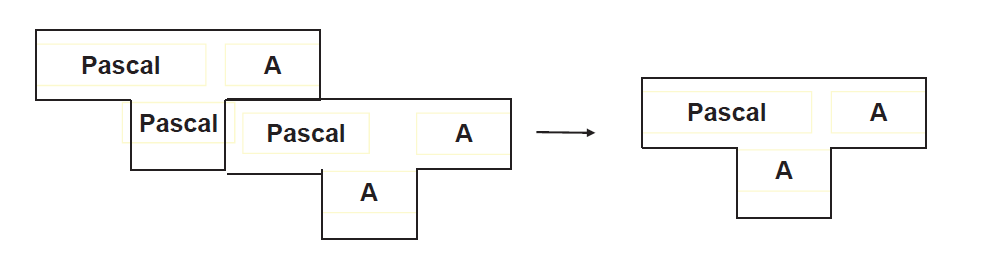
- 理解:可以用Pascal高级语言编写编译程序再用底层的A语言编译成A程序再用来编译Pascal程序,并非多此一举,可以优化代码,例如在编写的Pascal编译程序更加高级优化得更好
自展
先有一个a1语言核心部分构造的一个小小的编译程序,再通过类似自编译完成a2语言的编译程序,再用a2编译a3语言,从而可以构造a3的编译程序
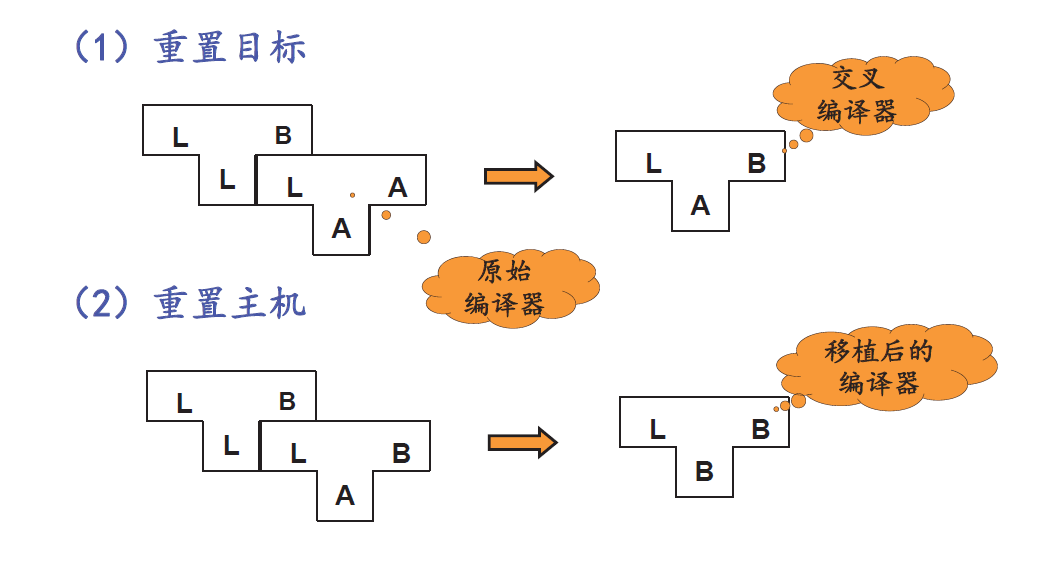
交叉编译器
L高级语言在A宿主机上实现能在B主机上运行的L语言
第二章形式语言概论
字母表 :元素的非空有穷集合,元素称为符号
符号串的前缀、后缀、子串都可以是空串,长度、连接、方幂、逆
符号串集合的乘积,和(+)就是并起来,乘就是连接前部分属于集合A后部分属于集合B,符号串集合的方幂就是集合的自乘积(0次方为空串),符号串集合的正闭包就是集合A从一次方幂累加到n次方幂,闭包就是包含零次幂
文法
- 终结符Vn:语言中不可分割的最小单元,组成句子的基本单元
- 非终结符VT:不是最终结果,而是一个占位符,可以继续细分的逻辑概念
- 产生式P:定义如何把非终结符转化为终结符或一串非终结符
1. 0 型文法 (Type-0 Grammar)
- 别名:短语结构文法、无限制文法。
- 规则特点:alpha -> beta。左边必须包含至少一个非终结符。
- 通俗理解:没有任何限制。你可以把一堆东西变成另一堆东西。它对应的能力最强,相当于“图灵机”,能计算任何可计算的问题。
2. 1型文法 (Type-1 Grammar)
- 别名:上下文有关文法 (Context-Sensitive Grammar)。
- 规则特点:产生的后面部分不能比前面短。
- 通俗理解:“变出来的东西不能缩水”。之所以叫“上下文有关”,是因为要把一个符号 A 替换掉,可能需要看它前后的邻居是谁。
- 例如:只有当 a 在 b 旁边时,A 才能变成 c。
3. 2 型文法 (Type-2 Grammar) —— 最核心
- 别名:上下文无关文法 (Context-Free Grammar, CFG)。
- 规则特点:A->beta。左边必须且只能是一个非终结符。
- 通俗理解:“不管你在哪,你就是你”。无论这个 $A$ 出现在句子的什么位置,它都可以直接按照规则替换,不需要看左右邻居(上下文)。
- 应用:绝大多数编程语言的语法(比如 C++、Python 的
if语句、循环语句)都是用 2 型文法描述的。
4. 3 型文法 (Type-3 Grammar)
- 别名:正规文法 (Regular Grammar) 或线性文法。
- 规则特点:A->a 或 A -> aB。
- 通俗理解:“排队生成”。每次替换只能产生一个终结符,或者一个终结符带一个非终结符。它非常有规律,像一串糖葫芦。
- 应用:正则表达式。主要用于识别“单词”(词法分析),比如判断一个字符串是不是合法的变量名或数字。
实例:
语言和语法树

【例1】 S -> aSb | ab
【例2】 S -> aSb | 空串
【例3】 S -> AB、 A -> aA | 空串、 B -> bB | b
【例4】 S -> AB、A -> aA | a、B -> bbB | b
【例5】 S -> aSbb | ab
【例6】
右线性 (Right Linear):非终结符在右边。
S -> 0A 、 A -> 10A | 空串
左线性 (Left Linear):非终结符在左边。
S -> S10 | 0
正规式 (Regular Expression):
S -> 0A
A -> 1S | 空串
- 正规式一次只能换出一个终结符
- 区分文法类型,先看左边如果左边出现了终结符,那么可能为0、1型文法,如果左边有且仅有一个非终结符则可能为2、3型文法,再看右边,(满足0、1)如果右边变短为0型,否则为1型,(满足2、3)如果一次产生多个非终结符则为2型否则为3型
- 规则规定: 在同一个文法中,左线性产生式和右线性产生式不能混用。一旦混用,它就降级为 2型文法(上下文无关文法) 了
与语法分析相关的几个概念
- 最左推导最右推导:在推导的每一步选择句型最左边/右边的非终结符进行替换
- 最左规约最右规约:总是先规约符号串中最左边/最右边可以被规约的部分
文法的使用限制
- 二义性:某个句子存在两颗及以上不同的语法树(存在两个或以上的最左或最右推导),消除二义性,语义加上限制或者重构
- 文法压缩:消除多余的产生式,产生式生成的是无法化简的,没用上的产生式,及有害产生式 S->S(避免二义性)
- 删除单规则:A -> B(把B替换)降低语法树的深度
- 删除空产生式 (也会导致二义性) A -> 空串

D可能为空,把D为空的情况带入 B有B -> 空串,同样要删除,B取值DD和D,对于A,原本BD都有可能为空,及可能有abD、aBb、ab,再把不为空正常情况带入及aBbD
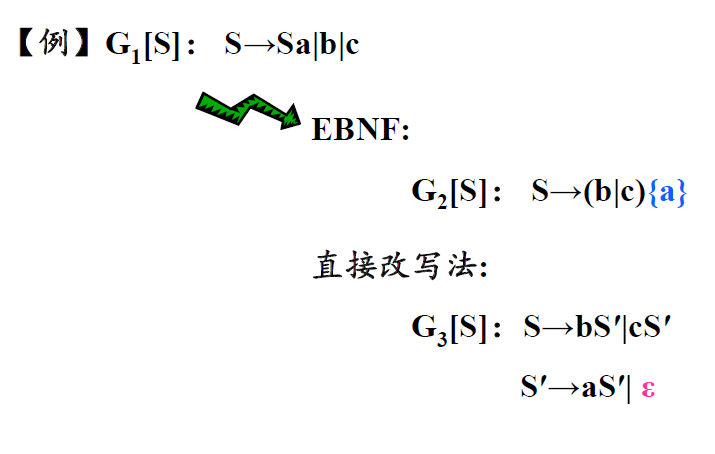
- 消除直接左递归(采用EBNF(){0/n}[0/1]方式)U->Uy
匹配待检查串:
- 自上而下:从S出发构造语法树,带回溯的方式,或者设计的时候限制文法,使其唯一确定,也就是线性的。
- 自下而上:从待检查串出发构造语法树,正常推导找最左规约
关于优先级的文法(加减乘除、交并补反)
1 | 【N】 实现交并括号取反优先级的文法且为左结合 |
为什么这么看?
你可以想象一下推导树(语法树)的生长方向:
- 左递归:为了匹配更多的输入,语法树会不断向左下方延伸。在最终生成的树中,最左边的运算节点处于树的最底层,因此会被最先计算。
- 右递归:语法树向右下方延伸,最右边的运算处于底层,最先计算。