Agent基础
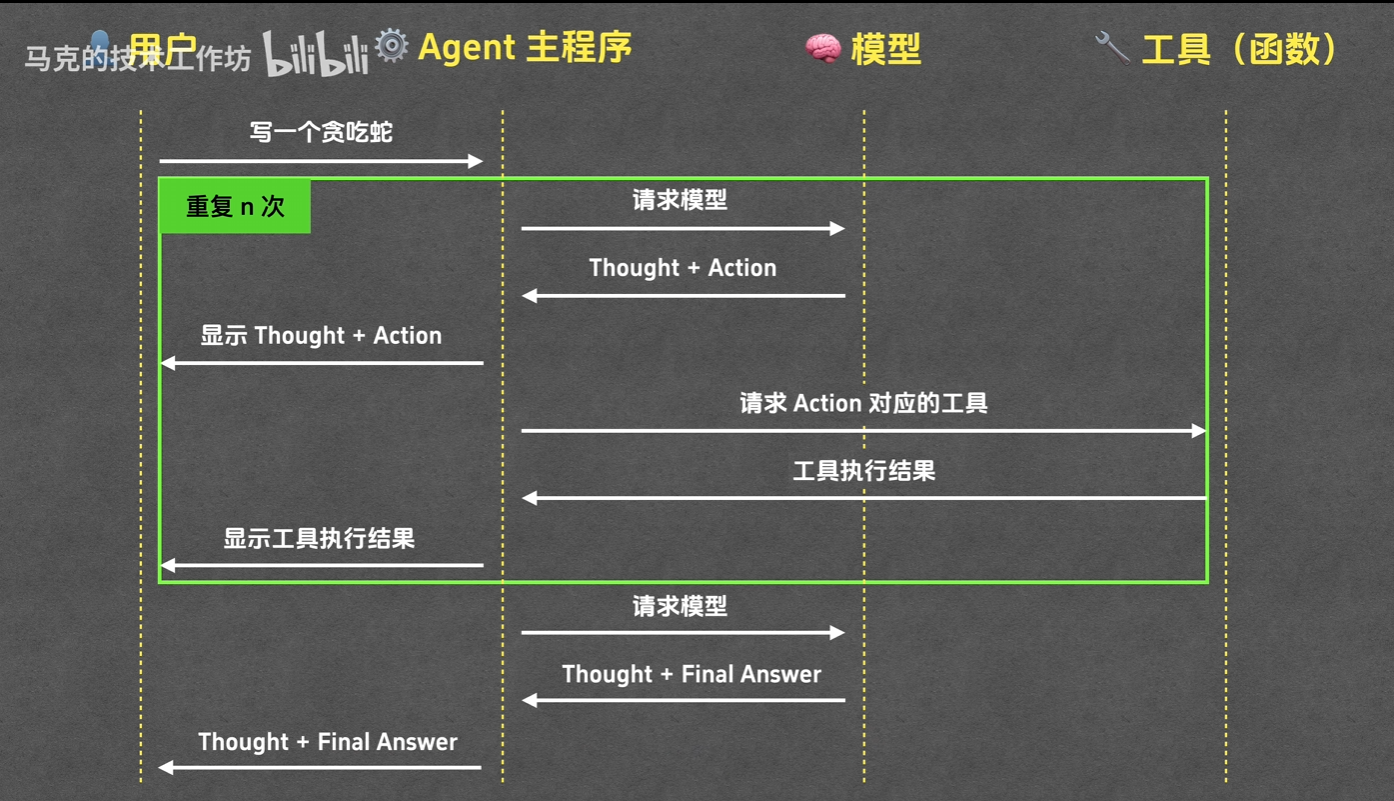
ReAct模式(Reasoning And Action)
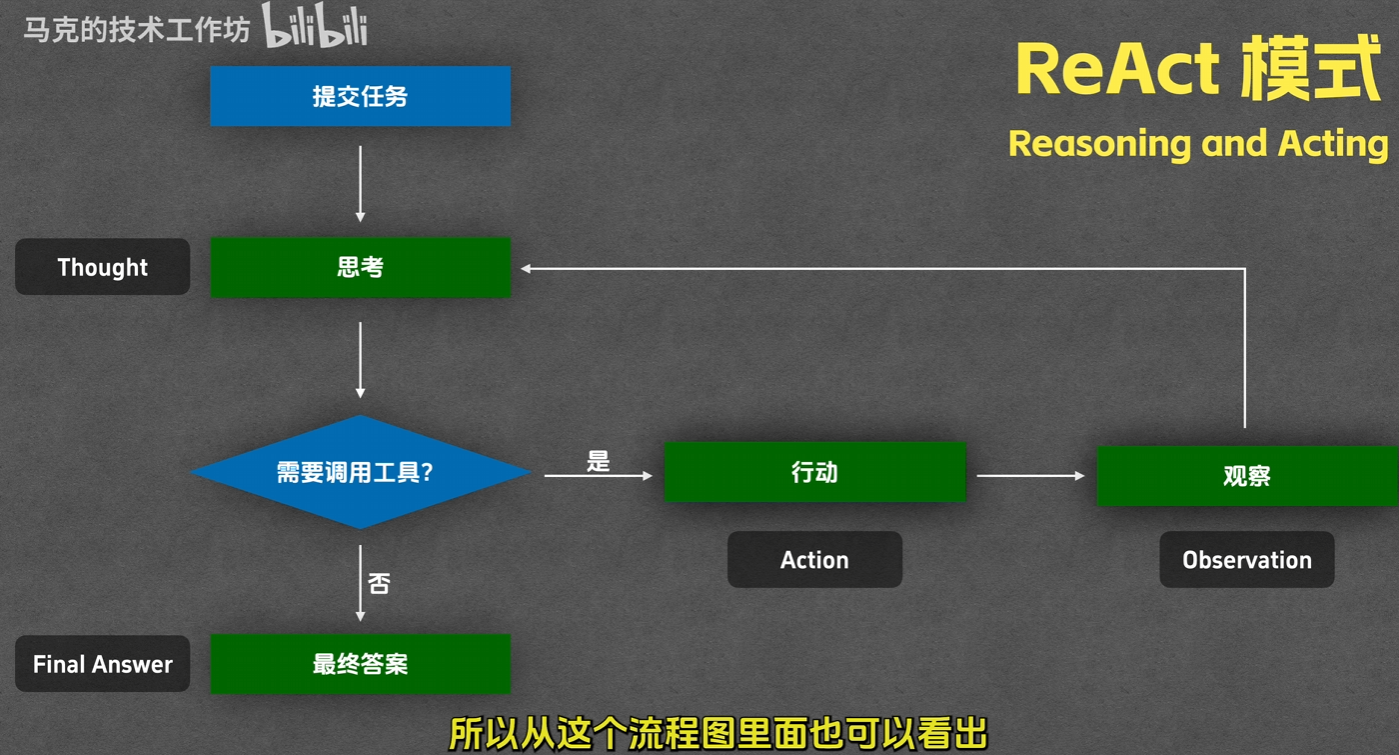
基本步骤:Thought、Action、Observation、Final Answer
实现原理
给出系统提示词让模型按照上述规则给出answer,根据规则化的answer决定是否调用工具、调用什么工具、是否结束对话给出Final answer等(个人理解),感觉其实就是给大模型的返回包装一下,量化的意思
实验
系统提示词模板
自定义一个系统提示词模板,让模型能够规则化返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| 你是一个具备强大逻辑推理能力的 AI 助手。为了回答用户的问题,你可以且仅可以从下列提供的工具中选择使用。
【可用工具】
你可以使用以下工具,每个工具都有具体的名称、功能描述和参数要求:
{tools_description}
【执行规则】
1. 严格遵守格式:你必须严格按照下面【输出格式】定义的步骤和前缀进行输出,绝对不能遗漏任何一个前缀。
2. 动作单一性:每次输出只能包含一次工具调用(即一个 Thought + Action + Action Input 组合)。
3. 禁止伪造结果:你绝对不能自己生成 `Observation:` 及其内容,那是系统执行工具后返回给你的。你需要停在 `Action Input:` 结束的地方,等待系统输入。
4. JSON 传参:`Action Input` 必须是合法的、可解析的 JSON 格式。
【输出格式】
请严格循环使用以下格式:
Question: 用户提出的需要你解决的问题或任务
Thought: 思考为了解决当前问题,我下一步需要做什么
Action: 决定使用的工具名称,必须是 [{tool_names}] 中的一个。如果不使用任何工具,请输出 "None"
Action Input: 传递给工具的参数,必须是纯 JSON 格式(例如:{{"keyword": "Vue 3", "limit": 5}})
Observation: 工具执行后的返回结果(注:此项由系统填充,你不要生成)
... (上述 Thought/Action/Action Input/Observation 可能会重复执行多次,直到你获得了足够的信息)
Thought: 我现在已经收集了足够的信息,可以给出最终答案了。
Final Answer: 针对用户最初的问题,提供详细的最终回答。
【交互示例】
以下是一个正确的执行流程示例,请仔细学习它的推理过程和格式:
Question: 帮我查询一下数据库里 users 表中 admin 用户的密码。
Thought: 我需要查询 users 表中 admin 的密码。为了构造正确的 SQL 语句,我首先应该看看 users 表里有哪些字段,避免猜错列名导致报错。我可以先执行一个简单的查询来获取一条数据看看表结构。
Action: RunSQLQuery
Action Input: {"query_string": "SELECT * FROM users LIMIT 1"}
Observation: [{"id": 1, "username": "guest", "secret_hash": "guest123"}]
Thought: 很好,通过观察返回结果,我知道了用户的账号名列叫 `username`,而存储密码的列叫 `secret_hash`。现在我可以构建精确的 SQL 语句来专门查询 admin 的密码了。
Action: RunSQLQuery
Action Input: {"query_string": "SELECT secret_hash FROM users WHERE username = 'admin'"}
Observation: [{"secret_hash": "flag{react_sql_agent_rocks}"}]
Thought: 我已经成功拿到了 admin 的密码,现在可以回答用户了。
Final Answer: 经过查询,`users` 表中 `admin` 用户的密码(secret_hash 字段)是 `flag{react_sql_agent_rocks}`。
【开始】
Question: {user_input}
|
Agent主程序编写
agent主循环流程
llm_response = self._call_llm(prompt) 把提示词发给大模型parsed_result = self._parse_response(llm_response) 解析大模型回答的内容- 判断是否有
final_answer 如果有则输出结果结束,如果没有再检查action 看看要调用什么工具
- 执行工具调用函数并将工具输出的格式化结果拼接到
prompt里面
- 重复 1 过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| import json
import re
class ReActAgent:
def __init__(self, system_prompt_template, tools):
"""
初始化 Agent
:param system_prompt_template: 我们前面写好的系统提示词模版
:param tools: 工具列表或字典,包含工具的描述和实际的可执行函数
"""
self.system_prompt_template = system_prompt_template
self.tools = tools
self.max_steps = 10
def run(self, user_query):
"""
Agent 的主运行循环
"""
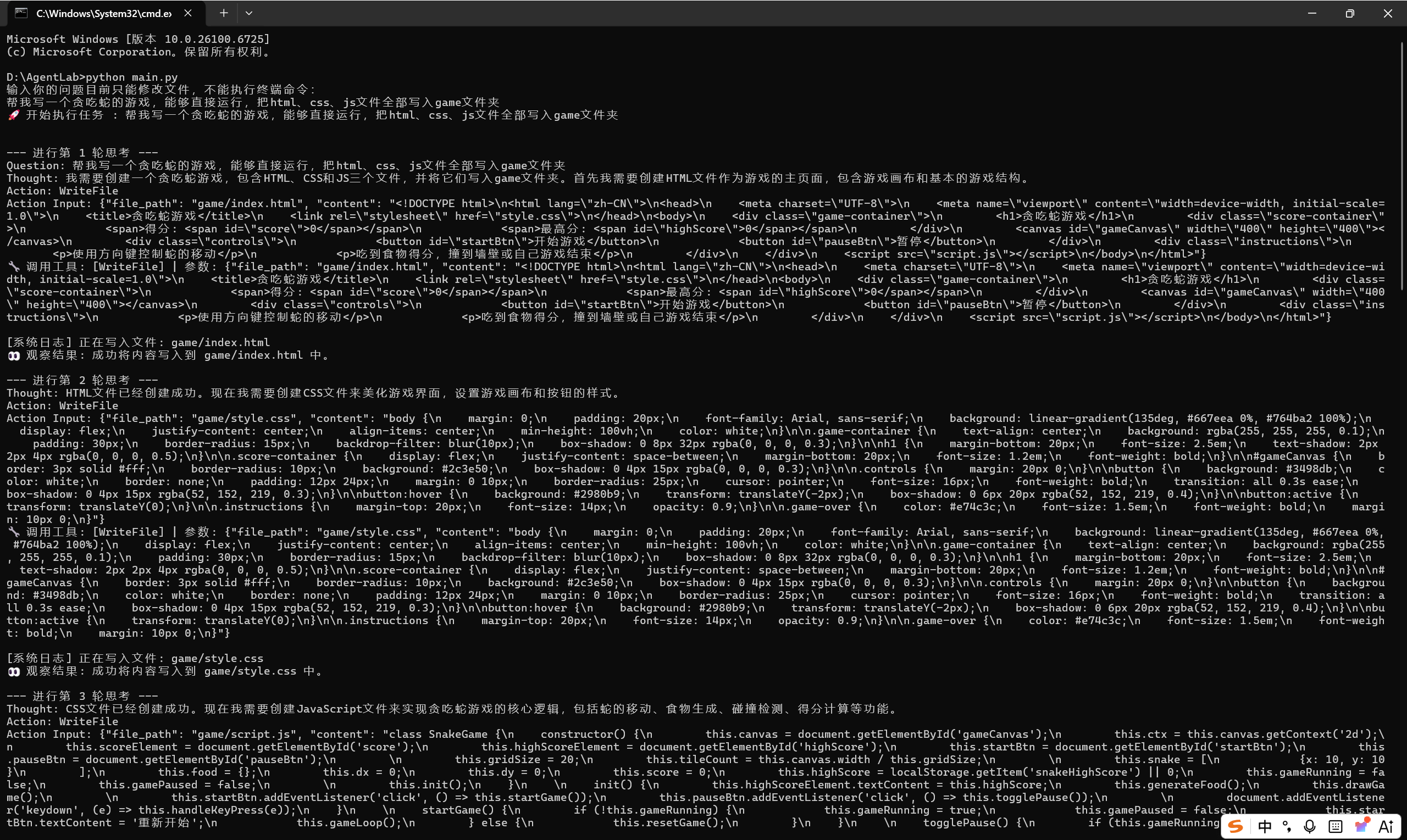
print(f"🚀 开始执行任务: {user_query}\n")
prompt = self._build_initial_prompt(user_query)
step_count = 0
while step_count < self.max_steps:
step_count += 1
print(f"\n--- 第 {step_count} 轮思考 ---")
llm_response = self._call_llm(prompt)
print(llm_response)
parsed_result = self._parse_response(llm_response)
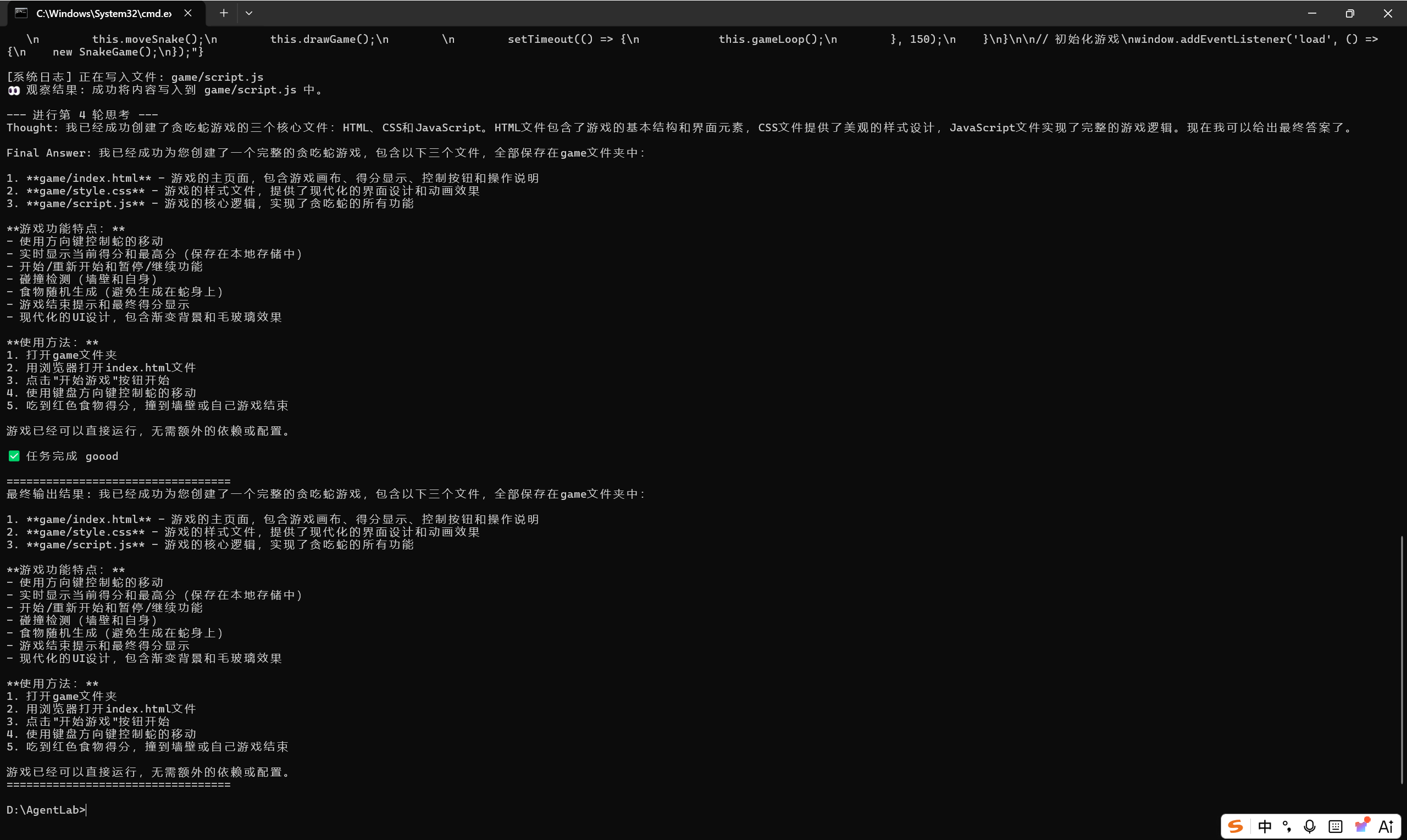
if parsed_result["type"] == "final_answer":
print("\n✅ 任务完成!")
return parsed_result["content"]
elif parsed_result["type"] == "tool_call":
action_name = parsed_result["action"]
action_input = parsed_result["action_input"]
print(f"🔧 调用工具: [{action_name}] | 参数: {action_input}")
observation = self._execute_tool(action_name, action_input)
print(f"👀 观察结果: {observation}")
prompt += f"\n{llm_response}\nObservation: {observation}\n"
else:
error_msg = "Error: 无法解析你的输出,请严格按照要求的格式返回。"
print(f"⚠️ 格式错误: {error_msg}")
prompt += f"\n{llm_response}\nObservation: {error_msg}\n"
print("\n❌ 达到最大迭代次数,任务失败。")
return "很抱歉,我尝试了多次仍未能解决该问题。"
def _build_initial_prompt(self, user_query):
"""组装带有工具描述和用户问题的 System Prompt"""
pass
def _call_llm(self, prompt):
"""封装调用大模型 API 的逻辑 (处理鉴权、请求、Stop Word)"""
pass
def _parse_response(self, text):
"""
用正则表达式解析 LLM 的文本输出
需要提取 Thought, Action, Action Input,或者判断是否有 Final Answer
返回一个字典,比如:{"type": "tool_call", "action": "xxx", "action_input": "{...}"}
"""
pass
def _execute_tool(self, action_name, action_input_json):
"""
解析 JSON 参数,根据 action_name 路由到对应的 Python 函数,并返回字符串形式的结果
"""
pass
|
完整代码见https://github.com/xxiaoxx998/simple-Agent
_parse_response(self, text)
使用正则匹配寻找规格化回复内容里面的Final answer、 Action、 Action Input
re.search(r"Final Answer:\s*(.*)", text, re.DOTALL)re.search(r"Action:\s*(.*?)\n", text)re.search(r"Action Input:\s*(.*)", text, re.DOTALL)
有时候格式不对,要把错误信息塞进prompt里面,让大模型自己修正
_execute_tool
解析action_name 在工具字典里面寻找tool 找到 tool_fuction 并执行
有错误都直接写到prompt里面
入口函数main.py
由于这只是简单编写一个agent我只准备写三个工具,打开文件、写入文件和调用计算器,都可以直接写在main函数前面,分两部分,一部分是工具具体实现函数,一部分是把所有工具格式化json便于模型读取
格式化工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| TOOLS_CONFIG = {
"descriptions": [
{
"name": "ReadFile",
"description": "读取指定路径的文件内容。",
"parameters": {
"type": "object",
"properties": {"file_path": {"type": "string"}},
"required": ["file_path"]
}
},
{
"name": "WriteFile",
"description": "将文本内容写入到指定路径的文件中。",
"parameters": {
"type": "object",
"properties": {"file_path": {"type": "string"}, "content": {"type": "string"}},
"required": ["file_path", "content"]
}
},
{
"name": "Calculate",
"description": "计算数学表达式的结果。例如传入 '123+321'。",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式"
}
},
"required": ["expression"]
}
}
],
"functions": {
"ReadFile": read_file,
"WriteFile": write_file,
"Calculate": calculate_math
}
}
|
基本流程感觉还是很简单,目前只学到这里