RAG(Retrieval-Augmented Generation)整体流程
先从外部知识库检索相关信息 → 把信息喂给大模型 → 模型基于事实生成回答
可以使用私有/最新的知识,简化文档
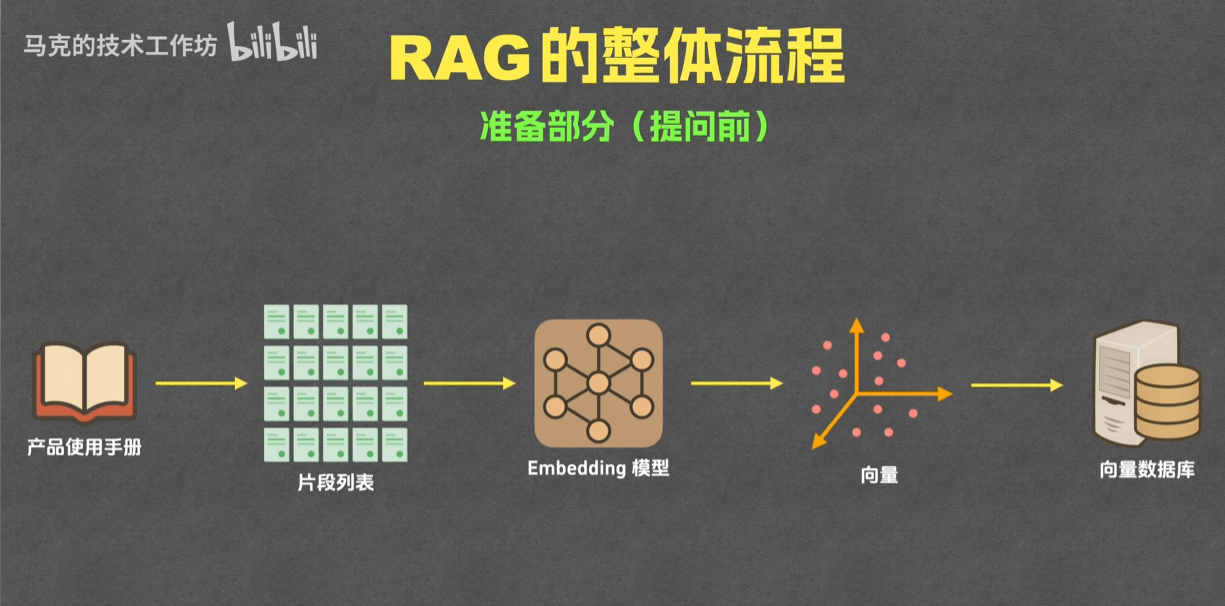
- 分片:根据已有的文本资源进行分段
- 索引:通过Embedding将片段文本转换为向量,再将片段文本和片段向量存入向量数据库
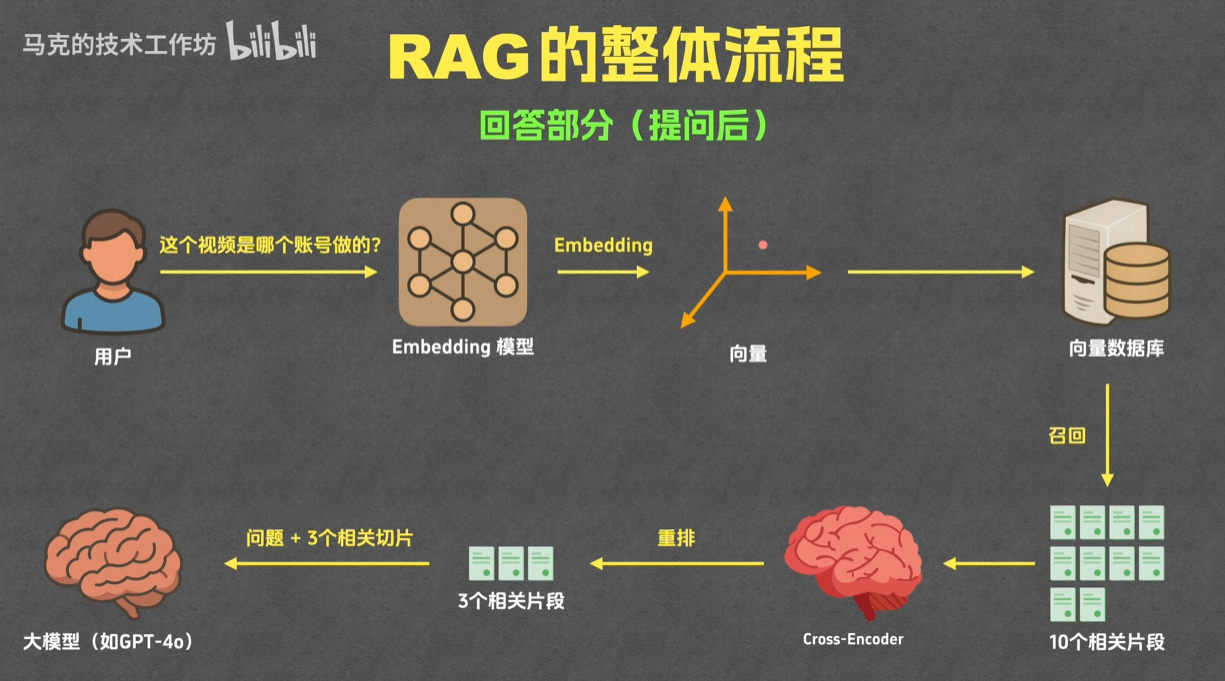
- 召回:首先将用户问题也通过Embedding转换为向量,然后再筛选出与用户问题向量相似度最高的一些进行初步筛选,快速但粗糙
- 重排:再次筛选,精度更高,算法更复杂,时间更长
- 生成:根据得到的用户问题和RAG得到的相关参考资料一起发送给大模型,大模型根据相关片段回答用户问题
主要使用三种模型:Embedding模型-分片,Cross-Encoder模型-重排,最后的语言模型-生成